3.4 Deep Neural Network(DNN)
3.4.1 LeNet5
LeNet5 诞生于1994年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从1988年开始,在许多次成功的迭代后,这项由 Yann LeCun完成的开拓性成果被命名为LeNet5(参见:Gradient-Based Learning Applied to Document Recognition)。

LeNet5的架构基于这样的观点:(尤其是)图像的特征分布在整张图像上,以及带有可学习参数的卷积是一种用少量参数在多个位置上提取相似特征的有效方式。在那时候,没有GPU帮助训练,甚至CPU的速度也很慢。因此,能够保存参数以及计算过程是一个关键进展。这和将每个像素用作一个大型多层神经网络的单独输入相反。LeNet5阐述了那些像素不应该被使用在第一层,因为图像具有很强的空间相关性,而使用图像中独立的像素作为不同的输入特征则利用不到这些相关性。
LeNet5特征能够总结为如下几点:
1)卷积神经网络使用三个层作为一个系列:卷积,池化,非线性
2)使用卷积提取空间特征
3)使用映射到空间均值下采样(subsample)
4)双曲线(tanh)或S型(sigmoid)形式的非线性
5)多层神经网络(MLP)作为最后的分类器
6)层与层之间的稀疏连接矩阵避免大的计算成本
总体看来,这个网络是最近大量神经网络架构的起点,并且也给这个领域带来了许多灵感。
3.4.1 AlexNet
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速,作者开源了他们在GPU上训练卷积神经网络的CUDA代码。AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%,相比第二名的成绩26.2%错误率有了巨大的提升。AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积网络)在计算机视觉的统治地位,同时也推动了深度学习在语音识别、自然语言处理、强化学习等领域的拓展。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下。
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256´256的原始图像中截取224´224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)2´2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。
整个AlexNet有8个需要训练参数的层(不包括池化层和LRN层),前5层为卷积层,后3层为全连接层,如图4所示。AlexNet最后一层是有1000类输出的Softmax层用作分类。 LRN层出现在第1个及第2个卷积层后,而最大池化层出现在两个LRN层及最后一个卷积层后。ReLU激活函数则应用在这8层每一层的后面。因为AlexNet训练时使用了两块GPU,因此这个结构图中不少组件都被拆为了两部分。现在我们GPU的显存可以放下全部模型参数,因此只考虑一块GPU的情况即可。

VGGNet
VGGNet网络架构于2014年出现在Simonyan和Zisserman中的论文中,《Very Deep Convolutional Networks for Large Scale Image Recognition》。该架构仅仅使用堆放在彼此顶部、深度不断增加的3×3卷积层,并通过max pooling来减小volume规格;然后是两个4096节点的全连接层,最后是一个softmax分类器。“16”和“19”代表网络中权重层的数量(表2中的D和E列):
在2014年的时候,16还有19层网络还是相当深的,Simonyan和Zisserman发现训练VGGNet16和VGGNet19很有难度,于是选择先训练小一些的版本(列A和列C)。这些小的网络收敛后被用来作为初始条件训练更大更深的网络——这个过程被称为预训练(pre-training)。VGGNetNet有两个不足:训练很慢;weights很大。由于深度以及全连接节点数量的原因,VGGNet16的weights超过533MB,VGGNet19超过574MB,这使得部署VGGNet很令人讨厌。虽然在许多深度学习图像分类问题中我们仍使用VGGNet架构,但是小规模的网络架构更受欢迎(比如SqueezeNet, GoogleNet等等)。
VGGNet附加话题 1 MSRA初始化,详见《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》 2 权重初始化以及深度神经网络的收敛,详见《All you need is a good init, Mishkin and Matas (2015)》
ResNet-50
与AlexNet、OverFeat还有VGG这些传统顺序型网络架构不同,ResNet的网络结构依赖于微架构模组(micro-architecture modules) 。 ResNet于2015年出现在Heetal的论文《Deep Residual Learning for Image Recognition》中,它的出现很有开创性意义,证明极深的网络也可以通过标准SGD(以及一个合理的初始化函数)来训练。 尽管ResNet比VGG16还有VGG19要深,weights却要小(102MB),因为使用了全局平均池化(global average pooling),而不是全连接层。
GoogLeNet Inception
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献1表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。 虽然数学证明有着严格的条件限制,但Hebbian准则有力地支持了这一点:fire together,wire together。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。对上图做以下说明: 1) 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合; 2) 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后, 只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了; 3) 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。 4) 网络越到后面,特征越抽象, 而且每个特征所涉及的感受野也更大了, 因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,使用5x5的卷积核仍然会带来巨大的计算量。为此,文章借鉴NIN2,采用1x1卷积核来进行降维。例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
本文的主要想法其实是想通过构建密集的块结构来近似最优的稀疏结构,从而达到提高性能而又不大量增加计算量的目的。GoogleNet的caffemodel大小约50M,但性能却很优异。
Xception
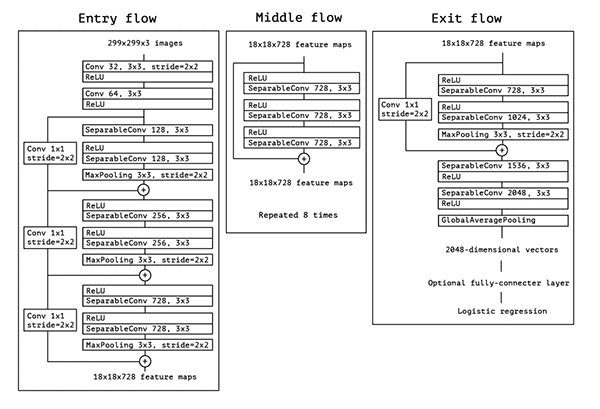 Xception是被François Chollet提出的, 后者是Keras库的作者和主要维护者。
Xception是Inception架构的扩展,用depthwise独立卷积代替Inception标准卷积。
关于Xception的出版物《Deep Learning with Depthwise Separable Convolutions》可以在这里找到。
Xception最小仅有91MB。
Xception是被François Chollet提出的, 后者是Keras库的作者和主要维护者。
Xception是Inception架构的扩展,用depthwise独立卷积代替Inception标准卷积。
关于Xception的出版物《Deep Learning with Depthwise Separable Convolutions》可以在这里找到。
Xception最小仅有91MB。
参考文献
1 GoogLeNet系列解读
2 GoogLeNet V1:Going deeper with convolutions
3 GoogLeNet V1:Rethinking the Inception Architecture for Computer Vision
4 ImageNet: VGGNet, ResNet, Inception, and Xception with Keras
5 CNN几种经典模型比较